Real-world multi-modal problems are rarely solved by a single machine learning model, and often require multi-step computational plans that involve stitching several models. Tool-augmented LLMs hold tremendous promise for automating the generation of such computational plans. However, the lack of standardized benchmarks for evaluating LLMs as planners for multi-step multi-modal tasks has prevented a systematic study of planner design decisions. Should LLMs generate a full plan in a single shot or step-by-step? Should they invoke tools directly with Python code or through structured data formats like JSON? Does feedback improve planning?
To answer these questions and more, we introduce m&m's: a benchmark containing 4K+ multi-step multi-modal tasks involving 33 tools that include multi-modal ML models, (free) public APIs, and image processing modules. For each of these task queries, we provide automatically generated plans using this realistic toolset. We further provide a high-quality subset of 1,565 task plans that are human-verified and correctly executable.

Dataset statistics of m&ms.
Overall,  m&ms contains a large quantity of diverse ecologically-valid task queries.
Each task is associated with human-verified and executable plans. Concretely, there are a
total of 4,427 raw examples in m&ms, where 1,565 have been verified to be correct by three human annotators.
After additional filtering, we select a subset of 882 examples for evaluation.
m&ms tasks are granular in difficulty with 70 queries that require a single tool, 159 need two tools,
and 653 need three tools. In terms of tools, there are 33 unique tools in total across three different
categories, of which 13 are multi-modal machine learning models on HuggingFace,
11 are image processing modules from VisProg, and 9 are free public
APIs from RapidAPI. Our final dataset includes 317 representative tool sequences
where each sequence consists of a mix of tools across categories and maps to multiple unique queries.
See a summary of the dataset statistics above.
m&ms contains a large quantity of diverse ecologically-valid task queries.
Each task is associated with human-verified and executable plans. Concretely, there are a
total of 4,427 raw examples in m&ms, where 1,565 have been verified to be correct by three human annotators.
After additional filtering, we select a subset of 882 examples for evaluation.
m&ms tasks are granular in difficulty with 70 queries that require a single tool, 159 need two tools,
and 653 need three tools. In terms of tools, there are 33 unique tools in total across three different
categories, of which 13 are multi-modal machine learning models on HuggingFace,
11 are image processing modules from VisProg, and 9 are free public
APIs from RapidAPI. Our final dataset includes 317 representative tool sequences
where each sequence consists of a mix of tools across categories and maps to multiple unique queries.
See a summary of the dataset statistics above.
You can download the different splits of the m&ms dataset via HuggingFace Dataset.
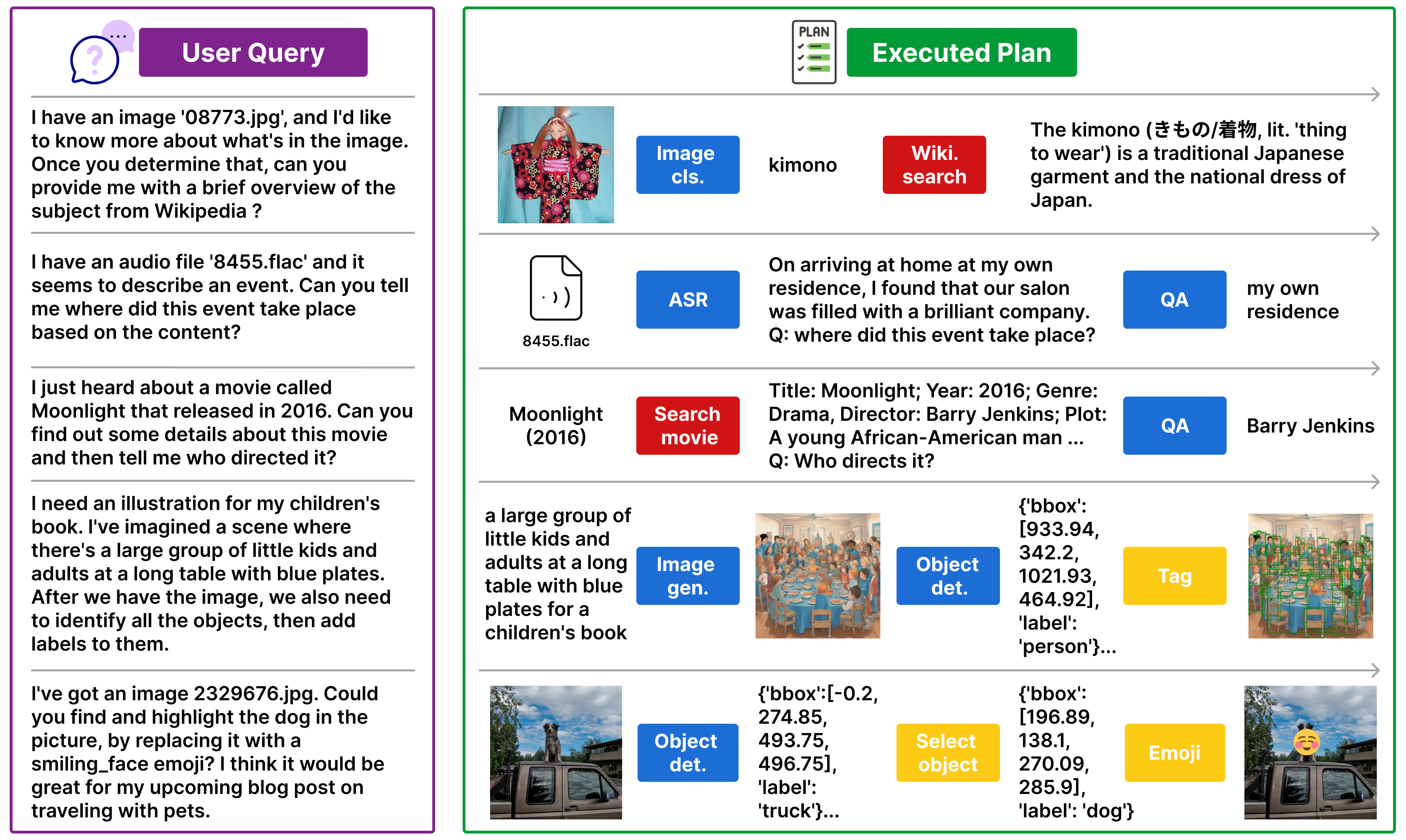
We present additional examples of query-plan pairs in the m&ms dataset below:

Ex1. 2-tool Query and Plan

Ex2. 2-tool Query and Plan

Ex3. 2-tool Query and Plan

Ex4. 2-tool Query and Plan

Ex5. 3-tool Query and Plan

Ex6. 3-tool Query and Plan

Ex7. 3-tool Query and Plan

Ex8. 3-tool Query and Plan

Ex9. 3-tool Query and Plan
In this section, you can find more details about the tools and their distributions in m&ms.

A complete list of tools across three categories in the m&ms dataset.
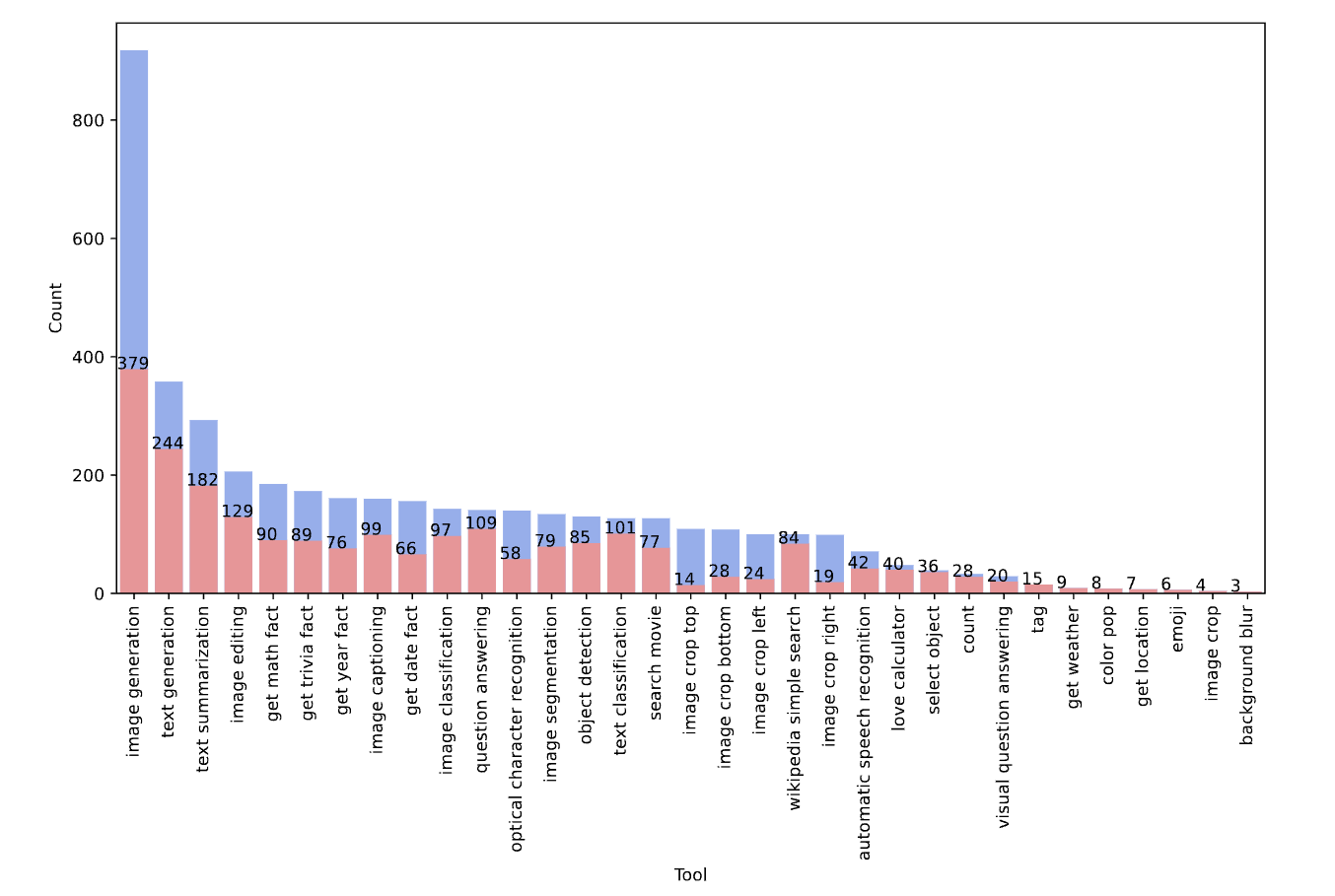
The distribution of tools before (blue) and after (red) data filtering. See more details about the filtering in our paper.
With m&m's, we evaluate 6 popular LLMs with 2 planning strategies (multi-step vs. step-by-step planning), 2 plan formats (JSON vs. code), and 3 types of feedback (parsing/verification /execution). We highlight three key findings from our extensive experiments:
We find that models consistently perform better on tool-F1 and pass rate when instructed to perform multi-step planning instead of step-by-step planning regardless of their sizes.
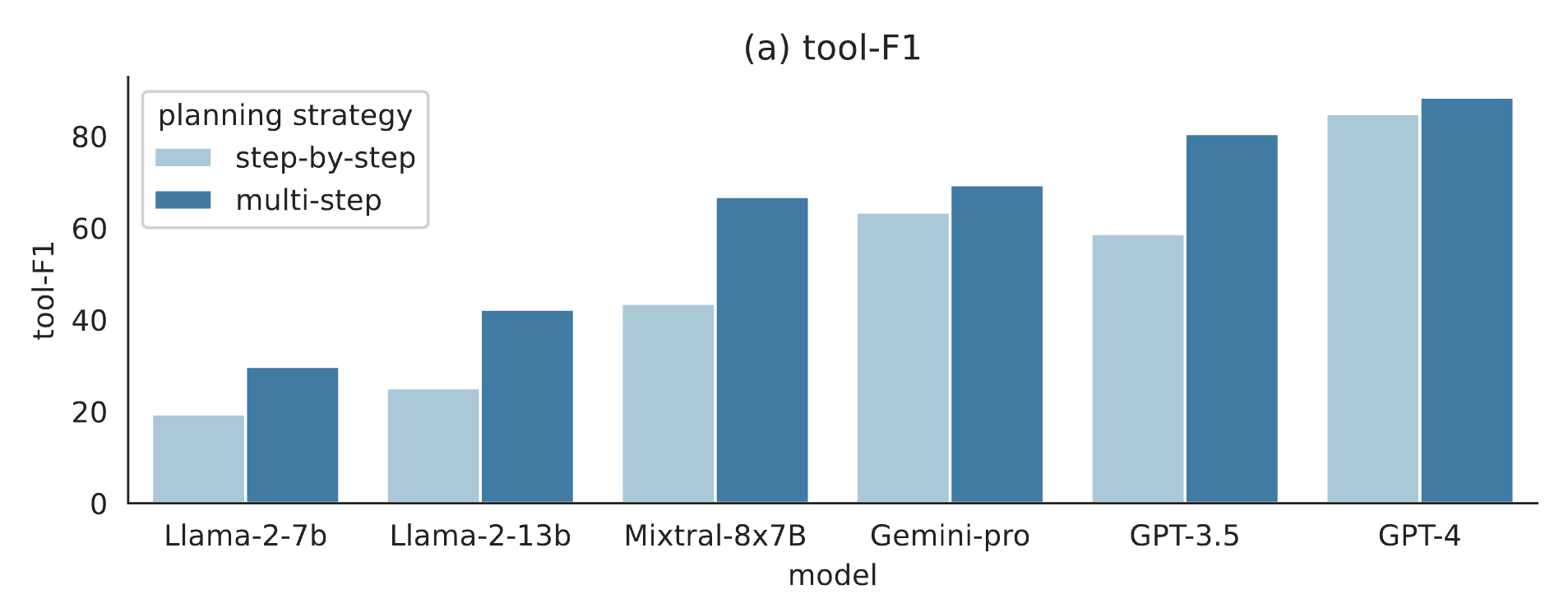
Tool-F1 of models under multi-step vs. step-by-step planning
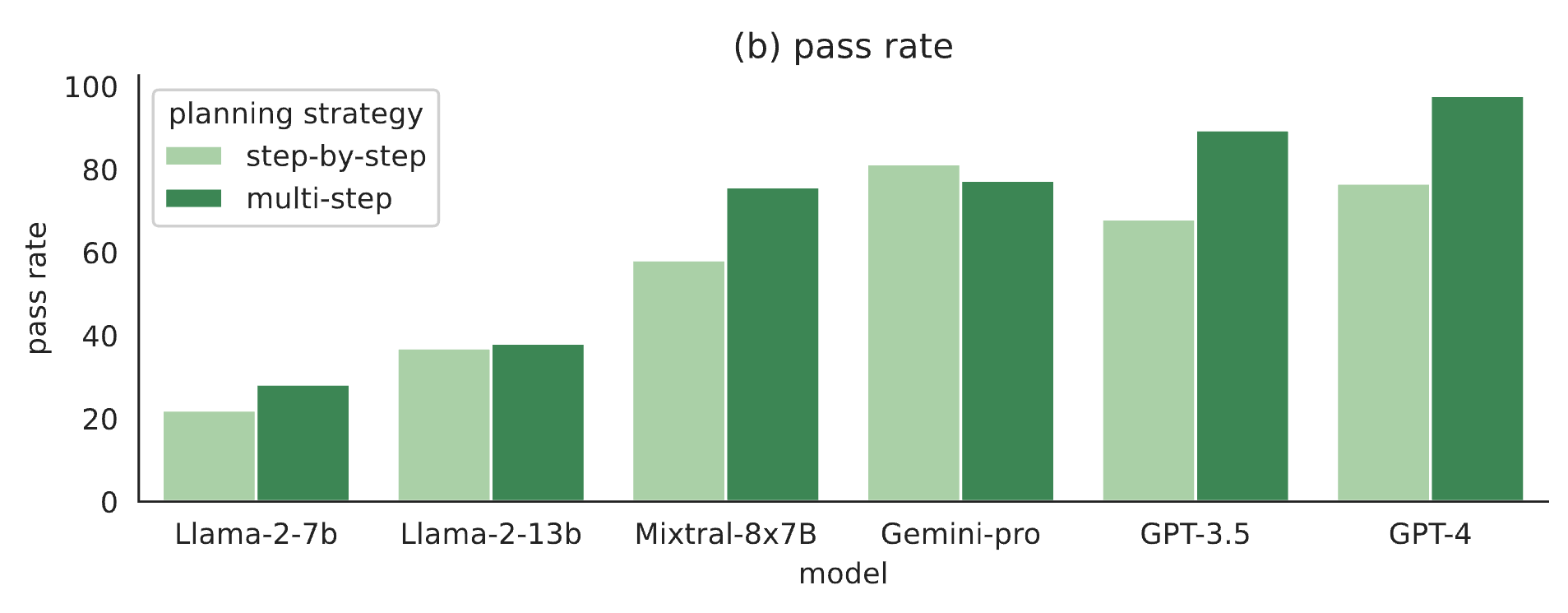
Pass rate of models under multi-step vs. step-by-step planning
External feedback can improve planning agents' performance on argname-F1 and pass rate at a small cost of tool-F1.
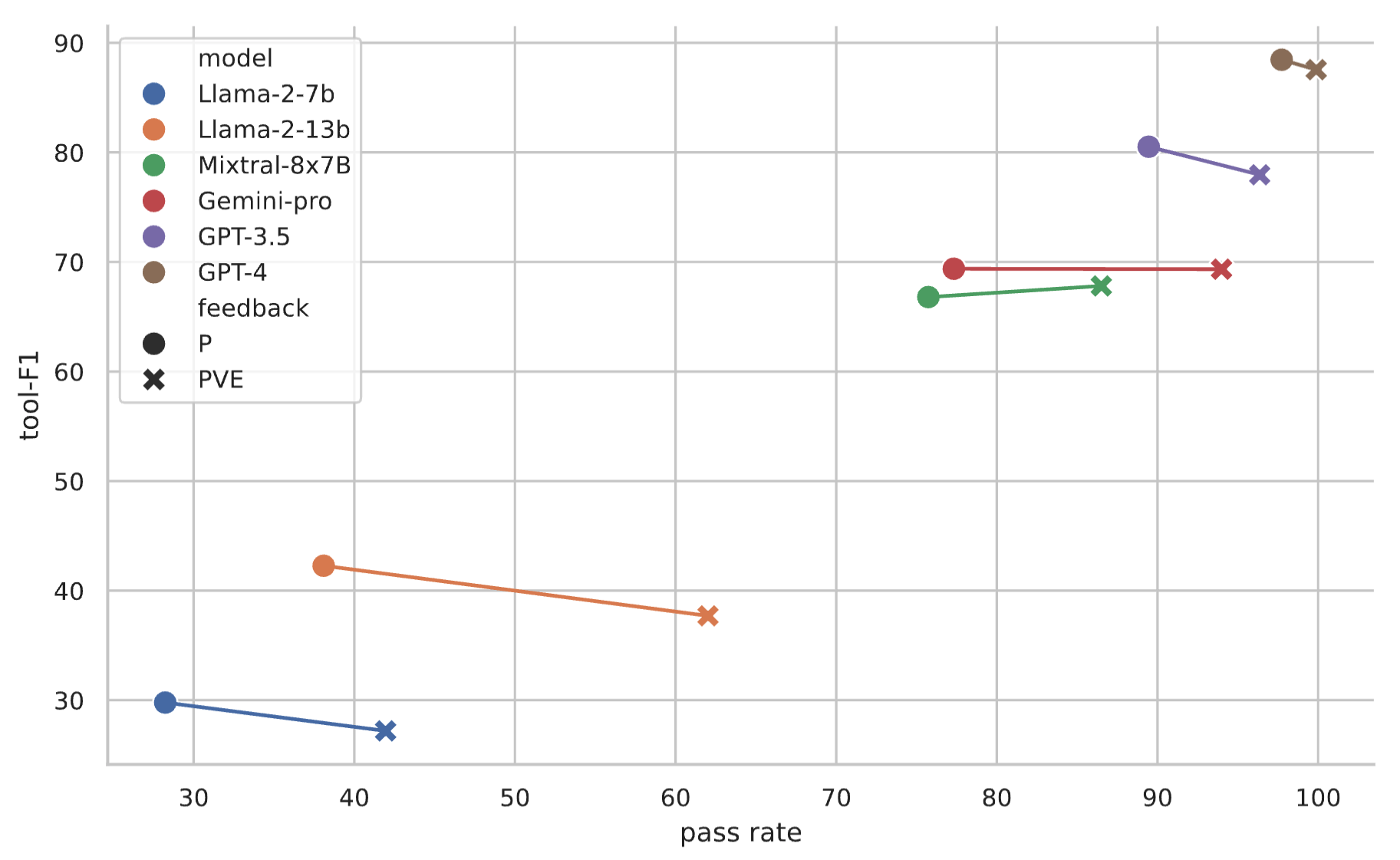
Tool-F1 and pass rate of models with or without verification and execution feedback
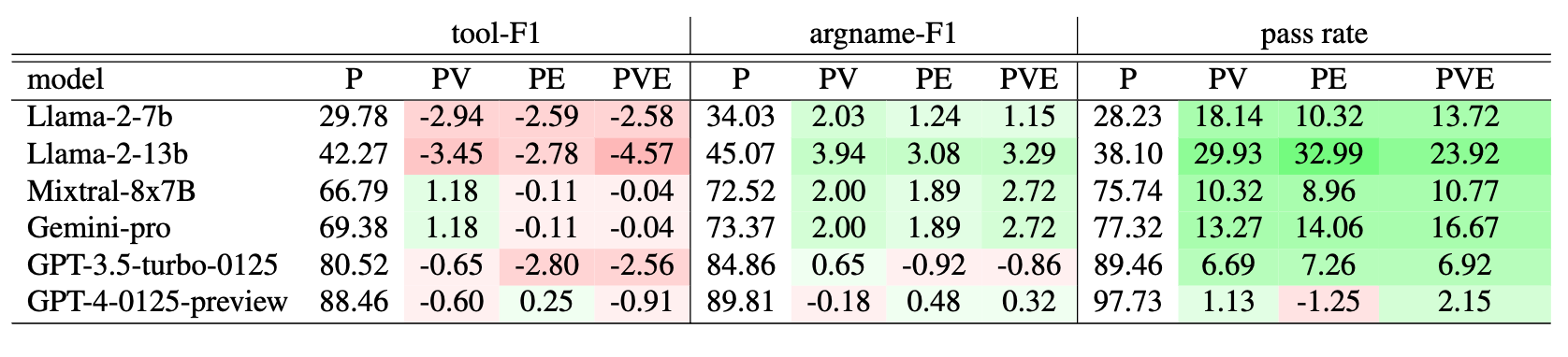
Tool-F1, argname-F1, and pass rate of models under multi-step planning with various feedback
Models perform comparably on tool-F1 with JSON- format and code generation but much worse on pass rate with code generation.
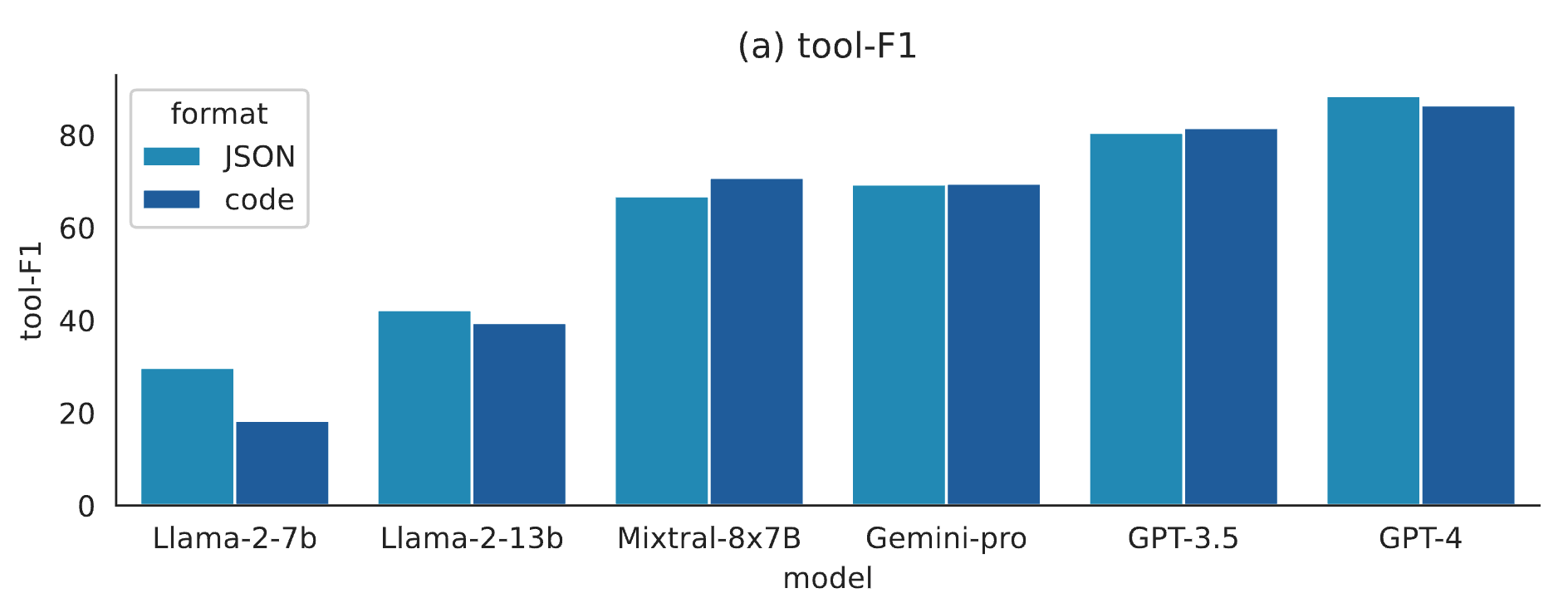
Tool-F1 of models with JSON-format vs. code generation
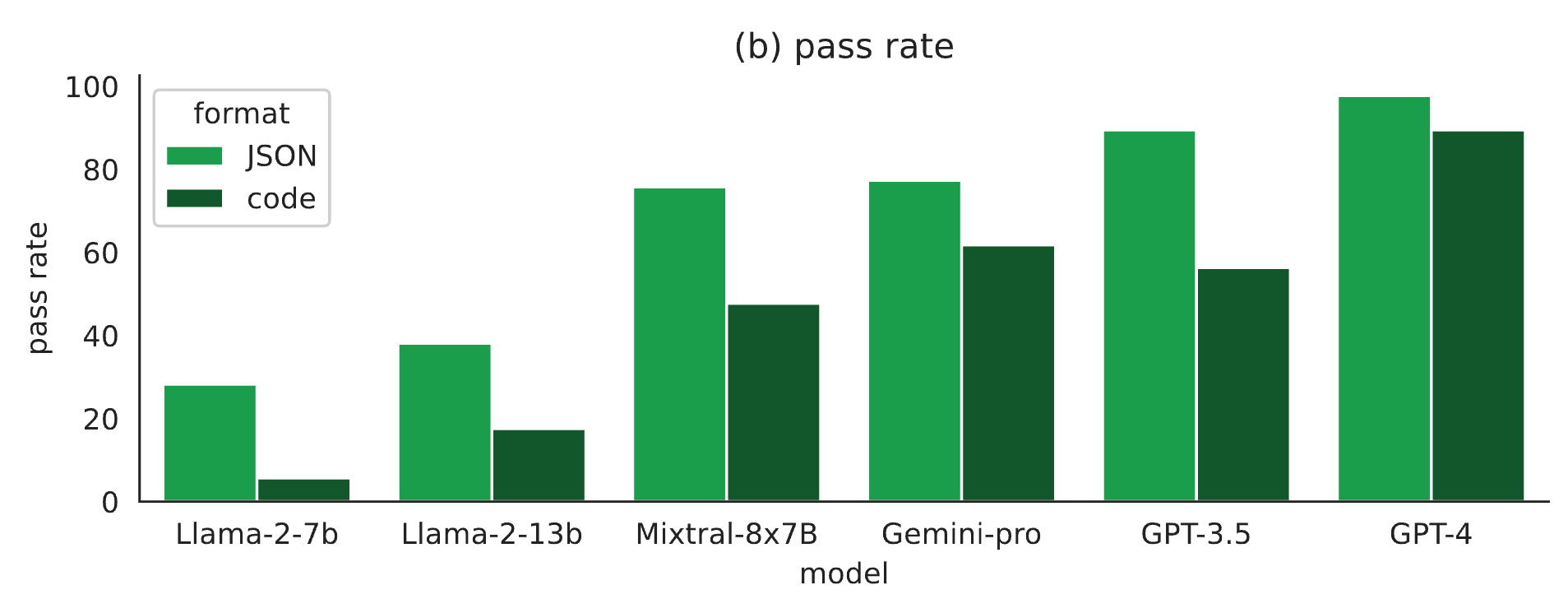
Pass rate of models with JSON-format vs. code generation
We provide examples of common errors observed in step-by-step planning, with verification/execution feedback, and in code generation.

Step-by-step planning (with parsing feedback)

Multi-step planning with verification/execution feedback

Code generation (with parsing feedback)
@article{ma2024mms,
title={m&m's: A Benchmark to Evaluate Tool-Use for multi-step multi-modal Tasks},
author={Zixian Ma and Weikai Huang and Jieyu Zhang and Tanmay Gupta and Ranjay Krishna},
year={2024},
journal={arXiv preprint arXiv:2403.11085},
}